데이터베이스 01일 정리
< 데이터 베이스 개론 시작 >
- 제 1장 : 데이터베이스 기본개념
1. 개요
2. 데이터베이스 정의
3. 데이터 처리 시스템
4. 파일관리 시스템 vs 데이터베이스 관리 시스템(DBMS)
5. 데이터 베이스 시스템역사
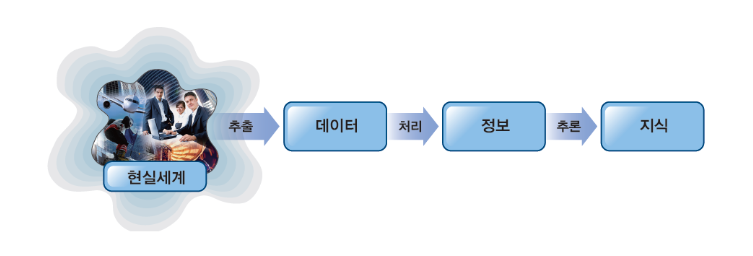
1.1 데이터와 정보
1) 데이터(data) : 현실세계로부터 관찰이나 측정 등의 수단을 통해 수집한 사실(facts)이나 값(values)
2) 정보(information)
- 데이터는 사실들 그 자체에 대한 일차적인 표현
- 사실들과 이들로부터 유도될 수 있는 유추된 사실들
- 틀정 상황에 대한 의사결정을 내릴수 있는 유용한 해석이나 데이터 상호간의 관계를 의미함.
※ 데이터(원본자료)와 정보(추출된 데이터)
1.2 메타데이터(Metadata)
- 데이터에 대한 데이터 (데이터 of 데이터 : 핵심데이터만 보관)
- 데이터의 구조(structure)나 제약사항(constraints) 등과 같은 속성(properties)이나
특성(characteristics)을 기술하는 것
('이름' - 속성 attribute-> 컬럼
행 (row, 튜플) , 열(colum, 컬럼)
각 열의 값들의 집합 = 도메인
유형은 사용되어지는 dbms에 따라서 명칭이 달라짐.)
1.3 지식(Knowlede) - 기계학습(ai 분야 쪽 사용)
2. 데이터베이스의 정의와 특성
2.1 데이터베이스의 정의
: DataBase
중복에 의한 데이터 불일치 최소화시키는 것.
특정 조직내에 다수의 사용자들이 공유할 수 있도록 통합시키고 컴퓨터 저장장치에
저장시킨 운영 데이터의 집합
1) 통합된 데이터(Integrated Data) : 자료의 중복을 배제한 데이터 모임
2) 저장된 데이터(Stored Dta):컴퓨터가 접근할 수 있는 저장매체에 저장된 자료
3) 운영 데이터(Operational Data) : 조직의 고유한 업무를 수행하는데 존재가치가 확실하고
없어서는 안될 반드시 필요한 자료
4) 공용 데이터(Sharaed Data) : 여러 응용시스템들이 공동으로 소유하고 유지하는 자료
※ SQL : 구조적 질의어. 사용자가 얻고싶은 자료를 얻을수 있도록 내리는 명령어.
(반복실행X/한번 실행하면 끝남. 기능이 약함.이해가 쉽지만 기능 한계점)
※ PLSQL : 변수 사용가용, 분기문, 반복문 사용 가능
데이터들은 명령에 의해 삽입, 삭제 할 수 있음.(조작어 수행) -> 데이터 변경
내용 변경이 휘발되기전에 하드디스크에 저장 시켜야 함. (comit/롤백rollback)
2.2 데이터베이스 특징
1) 실시간 접근(Real-Time Accessibility)
: 검색이나 조작을 요구하는 질의가 있을 때 현재 데이터 베이스에 수록된 데이터베이스를 사용하여
실시간으로 처리하고 응답하는 데이터베이스 시스템의 특성.
2) 계속적인 변화(Continuous Evolution)
: 데이터베이스의 상태는 동적임. 새로운 데이터의 삽입(Insert), 삭제(Delete), 갱신(Update)으로
항상 최신의 데이터를 유지
3) 동시 공유(Concurrent Sharing)
: 데이터베이스는 서로 다른 목적을 가진 여러 응용자들을 위한 것으로 다수의 사용자가 동시에
같은 내용의 데이터를 이용할 수 있어야 함.
4) 내용에 의한 참조(Content Reference)
: 데이터베이스에 있는 데이터를 참조할 때 데이터 레코드의 주소나 위치에 의해서가 아니라
사용자가 요구하는 데이터 내용으로 데이터를 찾는다.
3. 데이터 처리 시스템
3.1 일괄처리 시스템 VS 온라인 처리 시스템
1) 일괄처리 시스템 : 일정기간동안 데이터를 모아서 일시에 작업을 처리하는 시스템
2) 온라인 처리 시스템 : 작업 처리요구가 발생하면 즉시 시스템에서 처리함
3.2 오프라인 처리 시스템 VS 온라인 처리 시스템
1) 오프라인처리 시스템 : 특정작업을 처리하는 도중에 저장 데이터에 접근할 수 없는 시스템
2) 온라인 처리 시스템 : 작업 처리중 저장 데이터를 접근하여 사용할 수 있는 시스템
3.3 중앙집중처리 시스템 VS 분산 처리 시스템
1) 중앙집중 처리 시스템 : 중앙 컴퓨터에 데이터를 집중시켜 처리하는 시스템
2) 분산 처리 시스템 : 지역적으로 떨어져 있는 컴퓨터에 데이터를 분산시켜 처리하는 시스템
4. 파일관리 시스템 VS 데이터베이스 관리 시스템
4.1 파일관리 시스템 : 파일을 생성, 검색, 조작할 수 있는 소픝웨어 시스템
1) 파일관리 시스템 문제점
- 데이터의 중복이 심각하게 발생
- 데이터의 불일치가 발생 (삽입이상, 삭제이상, 갱신이상 등 오류 발생)
- 응용 프로그램이 파일의 형식에 종속
- 프로그래밍 언어마다 파일의 형식이 다름
※ 파일관리시스템을 개선.보완 => 데이터 베이스 관리 시스템
4.2 데이터베이스 관리 시스템(DBMS : DataBase Managment System)
1) 데이터베이스 관리 시스템의 장점
- 데이터의 중복이 줄어듬 (아예 없진 않음)
- 데이터의 불일치를 피할 수 있음
- 응용프로그램과 데이터의 독립성이 유지됨
- 응용프로그램과 데이터 형식의 표준화를 가함
- 데이터의 접근의 보안과 무결성 유지가 용이함
※ 참조 무결성 : 검색하고자 하는 데이터가 해당 테이블에 있는지 확인
2) 데이터베이스 관리 시스템의 단점
- 시스템을 이용하는 비용이 비쌈
- 파일관리 시스템을 이용하는 것보다 상대적으로 속도가 느림
(테스트 버전 출시 (처리데이터의 용량이 다를뿐 기능은 같음)/처리 속도가 느림)
※ 관계형 데이터베이스 시스템 : 테이블-테이블이 관계를 맺어야 하고. 동일한 칼럼(열)을 공유함
(부모-자식 테이블)
기본키가 있어야함 : null값이 아니여야함. 중복되서는 안됨
왜래키 : 자식테이블에서는 왜래키 사용
길이가 없는 데이터 : null (전체 컴퓨터 사용 개념) = white space
java 문자열 "" (쌍따옴표)
오라클 문자열 ''(그냥 따옴표)
다:다 개념적까지만 허용됨.
부모에 있는 기본키(상품번호/회원번호)를 자식(주문)이 기본키로 가져옴(중복 안됨)
5. 트랜잭션
: 논리적 기능을 수행하는 일련의 연산 집합 작업 단위 (반드시 comit이나 롤백으로 끝나야함)
회복 및 병행 수행시 처리되는 작업의 논리적 단위
※ 정상적 종료 : COMMIT(기억장치에 저장)
※ 비정상적 종료 : ROLLBACK. 트랜잭션 수행 전으로 돌아감
5.1트랜잭션의 특성
1) 원자성
: 트랜잭션의 처리는 완전히 끝마치치 않을 경우 해당 수행이 이루어지지 않는 것과 같아야 함
오류가 발생되면 그 트랜잭션은 모두 취소되야함.
모든 명령어를 완벽히 수행하여 comit 되지 않으면 안된다. 중간에 오류가 발생되면 철회한다(aborted)
2) 일관성
: 트랜잭션들 간의 영향이 한 방향으로만 전달되어야 한다.
수행을 성공적으로 완료 한 후 고정요소는 변동이 없어야 한다
<하나의 트랜잭션 수행>
구매테이블 => 판매테이블 : 날짜, 상품번호, 수량 저장 => 재고테이블에서 재고 관리
=> 회원테이블에서 마일리지 처리
이 수행 과정에 회원번호, 상품번호(고정요소)가 바뀌면 안된다. => 일관성
3) 고립성
: 하나의 트랜잭션이 수행되어 완료되지 않는 중간에 다른 트랜잭션이 접근하지 못하도록 한다
한 회원이물건을 구매해서 장바구니에서 구매내역 테이블을 자동으로 만들어줌 = 트리거
4) 지속성 : 성공적인 트랜잭션의 수행 후에는 반드시 데이터베이스에 영원히 반영해야 한다.