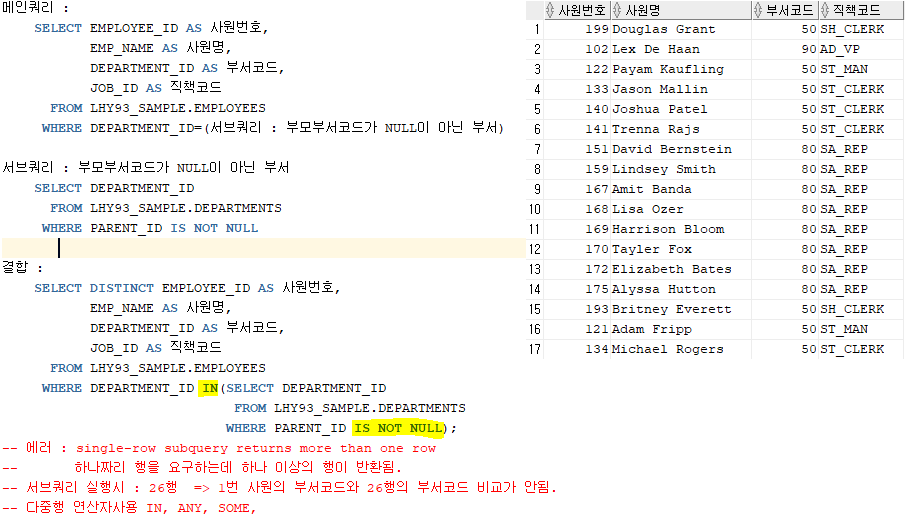
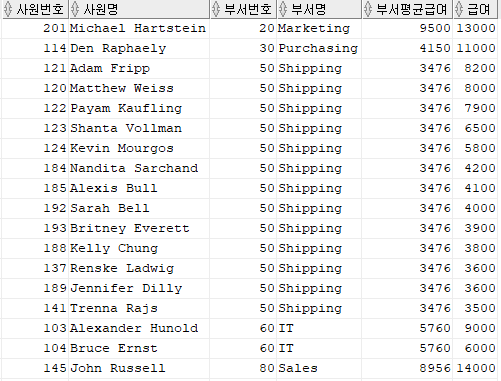
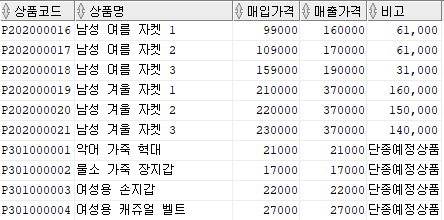
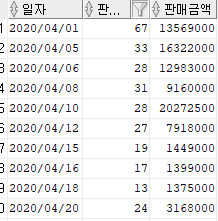
2. SEQUENCE
- 순차적으로 증가(감소)하는 값을 생성하는 오라클 객체
- 테이블과 독립적으로 수행
- 기본키로 선정할만한 컬럼이 존재하지 않는 경우, 자동적으로 증가하는 값이 필요한 경우 사용
(사용형식)
CREATE SEQUENCE 시퀀스명
[START WITH 시작값] -- 시작값/생략하면 MINVALUE값
[INCREMENT BY 값] -- 증(감)값
[MAXVALUE 값|NOMAXVALUE] -- 최대값 설정, 기본은 NOMAXVALUE이며 10^27
[MINVALUE 값|NOMINVALUE] -- 최소값 설정, 기본은 NOMINVALUE이며 1
[CYCLE|NOCYCLE] -- 최대[최소]값 까지 도달 후 다시 시퀀스를 생성할 지 여부. 기본은 NOCYCLE
[CACHE n | NOCACHE] -- 시퀀스를 생성하여 캐쉬에 저장할지 여부, 기본은 CACHE 20
[ORDER | NOORDER] -- 위 조건대로 시퀀스 생성을 보장할지 여부, 기본은 NOORDER
-- 시퀀스를 만들어 두고 쓰는 것 : 캐쉬
-- ORDER 정렬이 아니라 명령 이다.
- 시퀀스 값을 참조하기 위한 의사컬럼(Pseudo Column)
-------------------------------------------------
의사컬럼 내용
-------------------------------------------------
시퀀스명.NEXTVAL '시퀀스'의 다음 값 반환
시퀀스명.CURRVAL '시퀀스'의 현재 값 반환
*** 시퀀스가 생성된 후 처음 사용하는 명령은 반드시 NEXTVAL이어야 함
-- 시퀀스 전의 값 참조할 수 없음. CURRVAL값을 가지고 NEXTVAL값으로 가야 함.
사용예)
CREATE SEQUENCE SEQ_TEST
START WITH 10; -- SEQ_TEST 10부터 시작되는 시퀀스
SELECT SEQ_TEST.CURRVAL FROM DUAL;
-- CURRVAL is not yet defined in this session => NEXTVAL값을 써야함
SELECT SEQ_TEST.NEXTVAL FROM DUAL; -- = 10이 있는 위치로 감
SELECT SEQ_TEST.CURRVAL FROM DUAL; -- = 10
SELECT SEQ_TEST.NEXTVAL FROM DUAL; -- = 11
SELECT SEQ_TEST.CURRVAL FROM DUAL; -- = 11
SELECT SEQ_TEST.NEXTVAL FROM DUAL; -- = 12
-- 이후 10과, 11을 더이상 참조할 수 없음.
사용예) 분류테이블에 다음 자료를 삽입하시오
자료
-------------------------------------------------------------
LPROD_ID LPROD_GU LPROD_NM
-------------------------------------------------------------
시퀀스 사용 P501 농산물
시퀀스 사용 P502 수산물
시퀀스 사용 P503 농산가공식품

CREATE SEQUENCE SEQ_LPROD_ID
START WITH 10; -- 현재 LPROD 테이블 LPROD_ID SEQUENCE값 9
INSERT INTO LPROD VALUES(SEQ_LPROD_ID.NEXTVAL,'P501','농산물');
INSERT INTO LPROD VALUES(SEQ_LPROD_ID.NEXTVAL,'P502','수산물');
INSERT INTO LPROD VALUES(SEQ_LPROD_ID.NEXTVAL,'P503','농산가공식품');
SELECT * FROM LPROD;
**장바구니 번호 생성
-- 로그인되는 순간 계속 해당되는 장바구니 번호 부여함
-- 수행될때마다 실행되고 되돌아갈 수 없다. -- 시퀀스를 이용한 방법은 많이 사용하지는 않는다.
CREATE SEQUENCE SEQ_CART_NO
START WITH 1;
SELECT TO_CHAR(SYSDATE,'YYYYMMDD')||TRIM(TO_CHAR(SEQ_CART_NO.NEXTVAL,'00000'))
FROM DUAL;
-- 2022113000003
3. 동의어(SYNONYM)
- 오라클 객체에 부여하는 별칭
- 테이블 별칭은 해당 SQL문에서만 유효하지만 동의어는 테이블처럼 모든 곳에서 사용 가능
- 다른 소유자의 객체 접근시 긴 수식어 대신 짧고 사용하기 쉬운 별칭 부여에 사용
(사용형식)
CREATE [OR REPLACE] SYNONYM 동의어 FOR 객체명;
사용예) HR계정의 사원테이블과 부서테이블에 맞는 EMP 및 DEPT라는 동의어를 부여하시오
CREATE OR REPLACE SYNONYM EMP FOR HR.EMPLOYEES;
CREATE OR REPLACE SYNONYM DEPT FOR HR.DEPARTMENTS;
-- 접근 수식어를 포함하고 있는거에 동의어를 부여
SELECT * FROM DEPT;
SELECT EMPLOYEE_ID,EMP_NAME,SALARY
FROM EMP -- << 동의어 별칭 사용
WHERE DEPARTMENT_ID=50;
-- 50번 부서에 속한 사원의 사원번호,사원명,급여 조회
'DataBase' 카테고리의 다른 글
| 2022-11-30 데이터 베이스 오라클 SQL : PL/SQL (0) | 2022.11.30 |
|---|---|
| 2022-11-30 데이터 베이스 오라클 SQL : INDEX (0) | 2022.11.30 |
| 2022-11-30 데이터 베이스 오라클 SQL : 오라클객체 VIEW (1) | 2022.11.30 |
| 2022-11-25~8 데이터 베이스 오라클 SQL : SELF JOIN /서브쿼리 (0) | 2022.11.25 |
| 2022-11-23 데이터 베이스 오라클 SQL : NULL처리 함수 (0) | 2022.11.23 |