< 데이터베이스 설계 >
1. 요구사항 분석
2. 개념적 설계
3. 논리적 설계
4. 물리적 설계와 구현
▷ 데이터 베이스 설계 : 사용자(클라이언트 = 고객)의 다양한 요구사항을 고려하여 데이터 베이스를 생성하는 과정
▷ 관계데이터베이스의 대표적인 설계 방법
- E-R 모델과 변환 규칙을 이용한 설계 (Entity-Relationship Diagram)
- 정규화를 이용한 설계
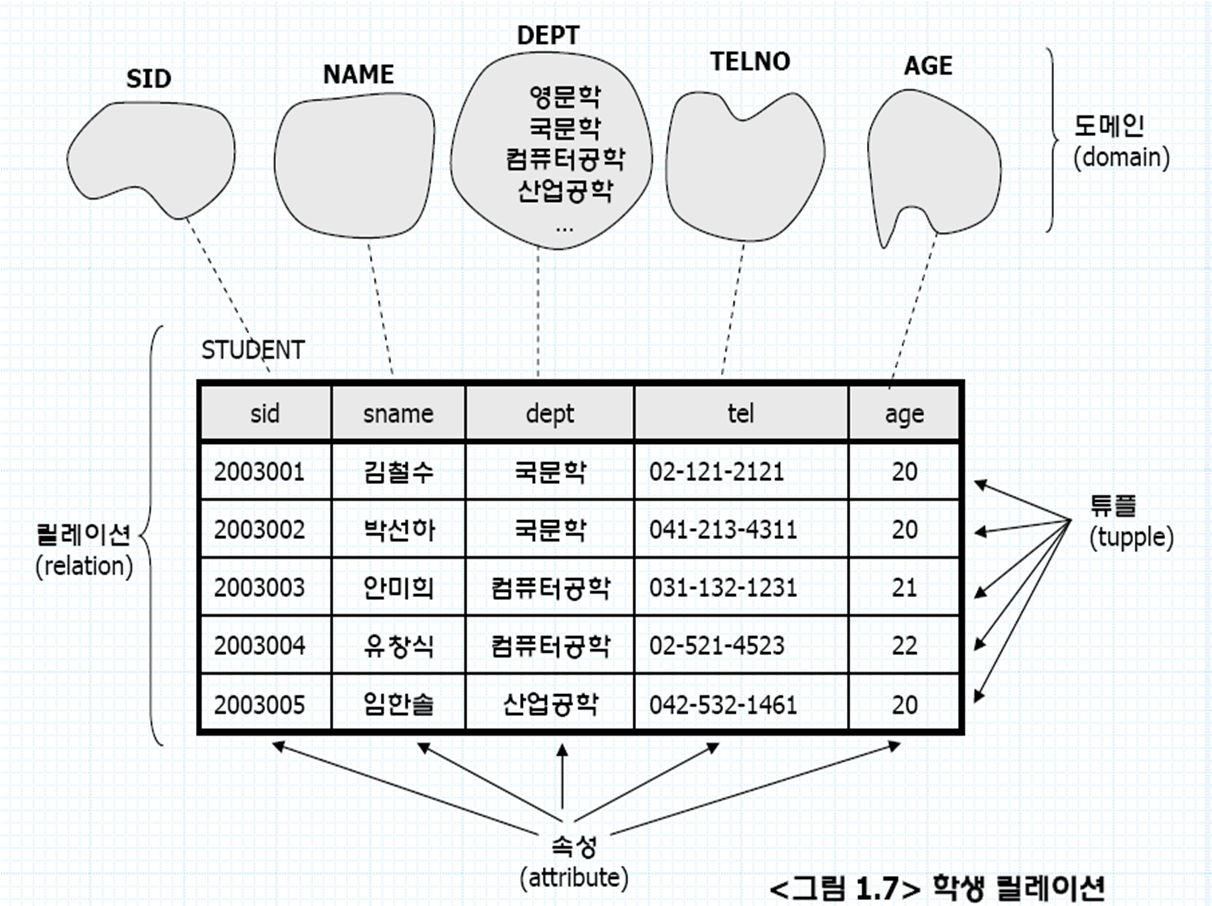
▶ E-R 모델과 릴레이션 변환 규칙


< 데이터베이스 설계 >
1. 요구사항 분석 ☞ 결과물 : 요구사항 명세서
: 사용자의 요구사항을 수집하고 분석 (업무에 필요한 데이터가 무엇인지)
▷ 주요 작업
1) 데이터베이스를 실제로 사용할 주요 사용자의 범위 결정
2) 사용자가 조직에서 수행하는 업무를 분석
3) 면담(인터뷰), 설문조사, 업무관련 문서 분석등의 방법을 이용해 요구사항 수집
4) 수집된 요구사항에 대한 분석결과를 요구사항 명세서로 작성
※ 검증할수 있는 도구 : USECASE 다이어그램(UML:Unified Modeling Language)
2. 개념적 설계 ☞ 결과물 : E-R 다이어그램(개념적 스키마)
: 요구사항을 분석한 결과에 따른 데이터베이스의 구성요소들을 판별
개념적 데이터 모델을 이용해 개념적 구조로 표현 ( 일반적으로 E-R 모델 이용)
요구사항 분석결과를 기반으로 중요한 개체(Entity)를 추출하고 개체간의 관계를 결정하여
E-R 다이어그램으로 표현
* E-R 다이어그램은 많은 공간을 차지한다.
▷ 주요 작업
1) 개체(Entity) 추출, 각 개체의 주요 속성과 키 속성 선별
2) 개체간의 관계(Relationship) 결정
3) E-R 다이어그램으로 표현(= 개념적 스키마)
(1) 개체 추출
* 개체 : 저장할만한 가치가 있는 중요 데이터를 가진 사람이나 사물을 나타내는 명사 추출
(고유명사 제외, 광범위한 의미의 명사는 제외, 의미가 같은 여러명사 여러개는 대표 하나만)
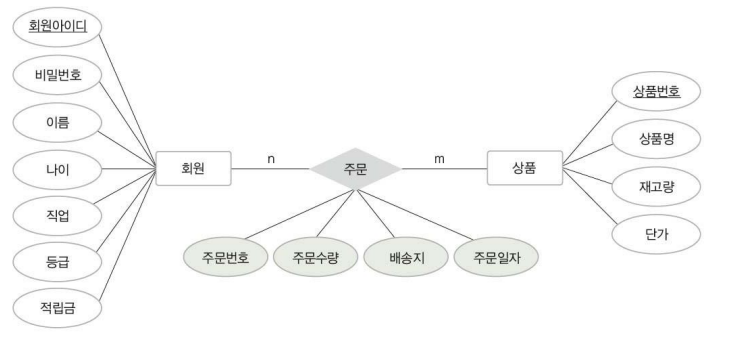
ex ) 한빛 마트에 회원으로 가입하려면 회원아이디, 비밀번호, 이름, 나이, 직업을 입력 가입한 회원에는 등급과 적립금이 부여된다. 회원은 회원아이디로 식별한다.
☞ 결과
개체 : 회원
'회원' 개체의 속성 : 회원아이디(식별자), 비밀번호, 이름, 나이, 직업, 등급, 적립금
'회원' 개체의 키 속성(식별자) : 회원아이디

(2) 개체간 관계 결정
: 동사를 찾아라. (2개의 명사 사이에서 기술하는 동사)
찾아낸 관계에 대해 매핑 카디널리티(차수) 특성 결정 = 1 : 1(일대일), 1 : n (일대다), n: m(다대다)
※ 다대다 관계는 개념적 모델에서만 가능하다.
ex ) 회원은 여러상품을 주문할 수 있고, 하나의 상품을 여러 회원이 주문할 수 있다.
회원이 상품을 주문하려면 주문에 대한 주문번호, 주문수량, 배송지, 주문일자 정보를 유지해야한다.
☞ 결과
회원 - 상품 ( 1: n 일대다)
관계 = '주문' / 관계는 속성을 가질수 있다.
'주문'-관계의 속성 : 주문번호, 주문수량, 배송지, 주문일자
3. 논리적 설계 ☞ 결과물 : 논리적 스키마 = 릴레이션 스키마(표)
- 개념적 설계의 결과물인 E-R다이어그램(개념적 스키마)을 사용
- DBMS에 적합한 논리적 스키마 설계
- 릴레이션(표)을 만듦. --------->> 추후 정규화 과정이 중요함. 정규화과정을 거쳐서 오류를 없앰
- DBMS의 종류가 설정됨 및 속성의 데이터 타입이 결정됨.
(데이터타입, 데이터 저장 길이, Null값 허용여부, Defualt 기본값, 제약조건 등)
▷ 주요 작업 : E-R 다이어그램을 릴레이션 스키마(표)로 변환
1) 규칙 1 : 모든 개체는 릴레이션으로 변환한다.
개체의 이름-> 릴레이션의 이름/식별자->기본키(pk)
복합속성인 경우 단순속성만 릴레이션으로 변환
주소(복합속성): 기본주소(단순)+상세주소(단순) => 주소를 지우고 단순속성만
2) 규칙 2 : 다대다(n:m) 관게는 릴레이션으로 변환한다 (개념적 설계에서만 표현 가능)
관계의 이름 : 릴레이션 이름
관계의 속성 : 릴레이션의 속성
3) 규칙 3 : 일대다(1:n) 관계는 왜래키(fk)로 표현한다
4) 규칙 4 : 일대일(1:1) 관계는 왜래키(fk)로 표현한다
5) 규칙 5 : 다중 값 속성은 릴레이션으로 변환한다. (제1정규화의 일부)

4. 물리적 설계 ☞ 결과물 : 물리적 스키마
DBMS로 구현 가능한 물리적 구조 설계
=> 분할된 테이블이 적절하게 분할 되었는지확인. 분할과 통합과정
테이블 설계에 대해서 경험과 지식이 겸비되었을때 할 수 있음.
한글 -> 실제로 구현시킬 영문명으로 바꿈
5. 구현 : SQL 문을 작성한 후 이를 DBMS에서 실행하여 데이터 베이스 생성
번외1)
2. 개념적 설계
회원->상품 1:다 상품->회원 1:다 => 다:다
주문서-결제(1:1) 혼인(1:1)
차수(카디널리티) : 1:1, 1:다, 다:다
E-R다이어그램 : 사각형 : 엔터티 / 마름모 : 관계(릴레이션쉽) / 타원 : 속성
소속 관계, 전체 차수 표현(부서->사원 1:다)
고객-상품(주문이라는 관계) 전체차수 다:다 = M : M
상품번호 : 상품을 구별하기위해 만듦 : 인조키
상품번호를 미리 만들수도 있다
요구사항에서 ->명사(주어, 목적어)로 추출 => 엔터티와 속성이 됨.
주종관계 주인: 엔터티(고유명사, 제외, 동의어는 한개만) , 종속된 것이 속성
회원-상품 동사 : 주문하다(상품, 회원-명사2개)=> 관계OK, 유지하다(주문-명사1개)=> 관계X
상품(엔터티)은 상품번호(식별자)로 식별한다.
제조업체(엔터티)는 제조업체명(식별자)으로 식별한다.
게시글(엔터티)은 글번호(식별자)로 식별한다.
번외2)
* 프로토타입 : 비용과 시간문제로 잘 안씀
* 한번에 모든것을 끝낼수는 없다.
* 개정이력 작성
* SVN 서버 : 개발 처음~끝까지 히스토리가 들어있음(두번째 프로젝트에 쓸것). 코드관리.버전관리
* 기준을 클라이언트(사용자) 위주로 생각하자
< 데이터베이스 모델링 E-R 설계 도구 설치 및 실습 >
EXERD 검색 -> 이클립스 기반 지능형 E-R 모델링도구
https://www.exerd.com
다운로드-플러드인->링크주소복사->이클립스 실행
->워크스페이스 주소 : D:\A_TeachingMaterial\02_Oracle 변경
->화면우측상단 워크벤치WORKBench?
help메뉴-인스톨 뉴 소프트웨어-Work with : http://exerd.com/update/exerd/3.x
이름 : eXERD 주소 : http://exerd.com/update/exerd/3.x
체크박스 체크 후 next-> 동의 -> finsh -> intalling software(설치중 확인)
이클립스에서 수행하는 작업의 종류
NEW-EXERD File-새프로젝트
다른 모델링 도구 엔코아 DA#5 (개념 모델링까지 지원 가능, BUT 어려움)
경고 메세지 => 이클립스만 RESTART? => RESTART NOW 선택
작업단위 퍼세티브 OPEN Perspective => eXERD 현재 등록안됨...=> 추후 재시도
D드라이브- 설치- 26 이클립스
< exerd 실습>
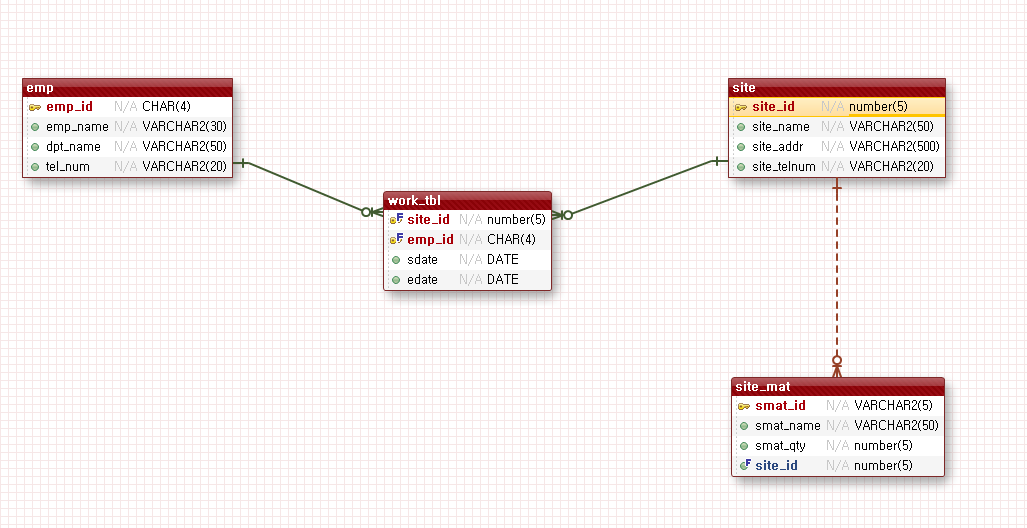
테이블 누르고 - 사원 -테두리 선택된 채로 스페이스바 : 속성
논리이름: 한글 /물리이름 : 영어
컬럼 : 기본키 더블클릭 : pk /열쇠모양 / 데이터타입 : char(n->4)
사원이름 데이터타입 : varchar2(30)
부서명 데이터타입 : varchar2(50)
N.N : not null
null : null을 허용하겠습니다.
사업장
사업장번호 데이터타입 : number(4)
=> 릴레이션 스키마로 변경
다대다 관계는 릴레이션으로 변경
부모키-자식키로 가져오면서 자식키의 기본키가 됨 : 왜래키(f)
사업장번호 : 고동색(기본키) / f: 왜래키 / 근무의 사원번호 : 일반 컬럼(f) 군청색
사업장이 부모이고 사업장 자재가 자식(1:다 => 다 : 자식)
사업장 자재명코드로 이미 구별할 수 있기 때문에 사업장-사업장자재는 비식별 관계이다
=> 논리설계 끝
exerd 메뉴
포워드 엔지니어링 : 순공학 => 테이블을 만들수 있는 코드가 나온다
리버스 엔지니어링 : 역공학
※ 데이터 입력할때도 부모키 먼저 입력하고 자식키 입력
'DataBase' 카테고리의 다른 글
| 22111~14 데이터 베이스 오라클 SQL : 연산자 (0) | 2022.11.16 |
|---|---|
| 221115 데이터 베이스 오라클 SQL : 기타 연산자 (0) | 2022.11.16 |
| 데이터베이스 04일 정리 - 정규화 과정과 함수종속성 (0) | 2022.11.12 |
| 데이터베이스 02일 정리 (0) | 2022.11.11 |
| 데이터베이스 01일 정리 (0) | 2022.11.11 |