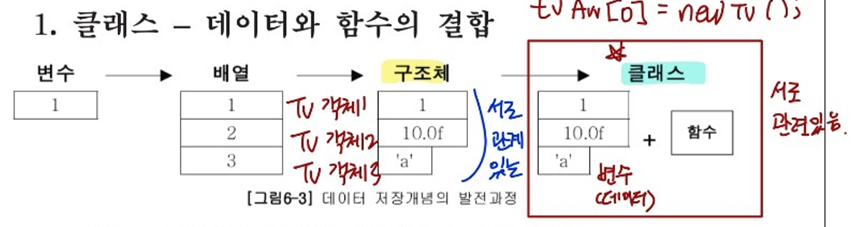
상속 (Inheritance)
- 기존의 클래스를 재사용해서 새로운 클래스를 작성하는 것.
- 두 클래스를 부모와 자식으로 관계를 맺어주는 것
- 자손은 조상의 모든 멤버를 상속받는다. (생성자, 초기화 블럭 제외)
- 자손의 멤버 개수는 조상보다 같거나 많다.
- 자손의 변경은 조상에 영향을 미치지 않는다.
자식이 새로운 멤버를 추가해도 부모클래스에는 영향이 없다.
class 자식클래스 extends 부모클래스 {
//
}
public class Point { //2차원 좌표의 한 점 (x,y)
int x;
int y;
}
//3차원 좌표
1)
class Point3D { //Point 클래스와 전혀 연관 없음
int x;
int y;
int z;
}
2) // 자식 부모
class Point3D extends Point { //상속관계로 영향을 받는다.
int z;
}
Point3D p = new Point3D(); // 결과는 똑같다.
예제)
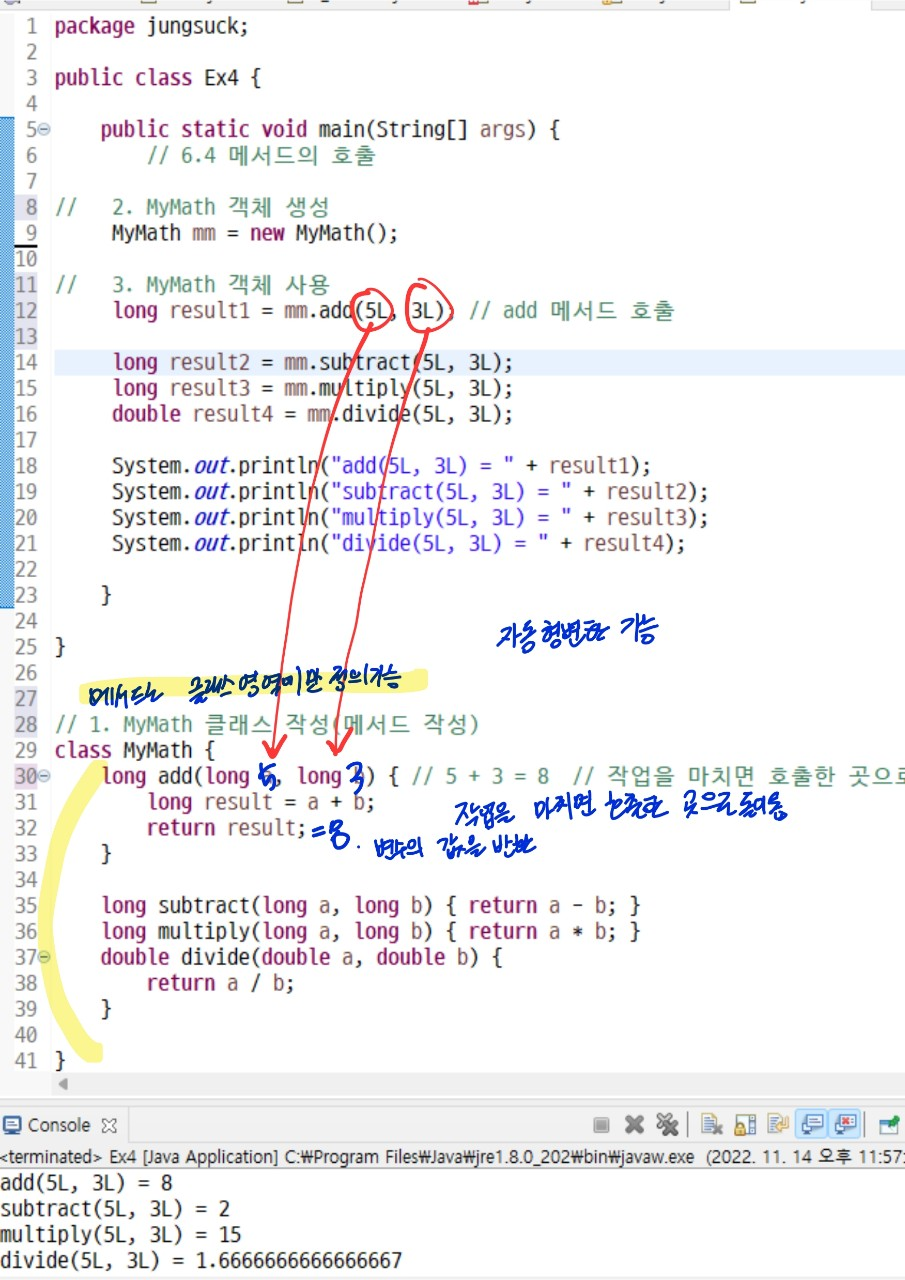
public class Tv {
boolean power; //전원상태(on/off)
int channel;
void power () { power = !power;}
void channelUp() { ++channel; }
void channelDown() { --channel; }
}
class SmartTv extends Tv { //SmartTv는 Tv에 자막(caption) 보여주는 기능
boolean caption; //caption상태 (on/off)
void displayCaption(String text){
if(caption) { //caption상태가 true(on) 일때만 text를 보여준다.
System.out.println(text);
}
}
}
class Ex_7{
// 메인 메서드 실행
public static void main(String[] args) {
SmartTv stv = new SmartTv();
stv.channel = 10; // 상속받은 부모의 변수를 쓸 수 있다
stv.channelUp(); // 싱석받은 부모의 메서드를 쓸 수 있다.
System.out.println(stv.channel);
stv.displayCaption("Hello, world"); //자신이 가진 메서드 실행
stv.caption = true;
stv.displayCaption("Helle, world");
}클래스의 관계 - 상속과 포함
포함
클래스의 멤버로 참조변수를 선언하는 것

class Car {
// 포함
Engine e = new Engine;
Door[] d = new Door[4];
}
클래스 간의 관계 결정하기
상속관계 : A은 B이다 (is - a)
포함관계 : A는 B를 가지고 있다 (has - a)
원은 점이다. (상속)
원은 점을 가지고 있다. (포함)=> 더 자연스러움
90% 포함이다.
상속은 꼭 필요할때만 쓰자
다형성
- 조상타입 참조변수로 자손타입객체를 다루는 것
// 기존
TV t = new TV(); // 타입 일치
SmartTv s = new SmartTv();
// 다형성
TV t = new SmartTv(); //타입 불일치 해도 OK
(부모) (자식)
▶ 객체와 참조변수의 타입이 일치할 때와 일치하지 않을 때의 차이?
= 조상타입의 참조변수로 자손타입의 객체를 다룰 수 있는 것이 다형성.

※ 자손타입의 참조변수로 조상타입의 객체를 가리킬 수 없다.
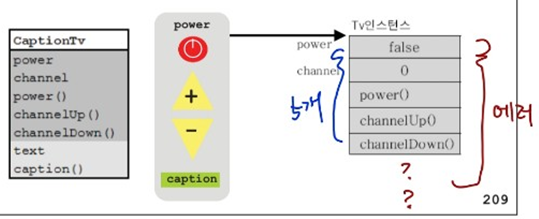
TV t = new SmartTv(); // OK
(부모멤버 5개) < (자식멤버 7개)
SmartTv t = new Tv(); //에러!!
(자식멤버 7개) > (부모멤버 5개)
참조변수의 타입은 인스턴스의 타입과 반드시 일치해야 하는가?
=> 일치하는 것이 보통이지만 일치 하지 않을 수도 있다.
참조변수가 조상타입일 때와 자손타입일때의 차이?
=> 참조변수로 사용할 수 있는 멤버 갯수가 달라짐.
자손타입의 참조변수로 조상타입의 객체를 가리킬수 있는지?
=> NO !!
참조변수의 형변환
: 사용할 수 있는 멤버의 갯수를 조절하는 것.
- 조상,자손 관계의 참조변수는 서로 형변환 가능
- 형제끼리는 형변환 불가
class Car { // 멤버 4개 // .water() 없음
String cololr;
int door;
void drive() { System.out.println("drive~~");}
void stop() {System.out.println("stop~~~");}
}
class FireEngine extends Car {
void water() {System.out.println("water~~~");}
}public static void main(String[] args) {
Car car = null;
FireEngine fe = new FireEngine();
// FireEngine fe2 = null;
FireEngine fe2 = (FireEngine)car; // 조상 -> 자손으로 형변환
Car car2 = (Car)fe2; // 자손 -> 조상으로 형변환
// car2.drive(); // 에러 : NullPointerException
//car2는 객체생성을 안해서 값이 null이기 때문에!!
//형변환 할때 실제 인스턴스(객체)가 무엇인지 중요하고
//그것을 넘지 않는게 중요하다.
fe.water();
car = fe; // car = (Car)fe 생략가능
// car.water(); //에러 Car타입으로는 .water() 사용 불가
fe2 = (FireEngine)car; // 자손타입 <- 조상타입 형변환 ()생략불가
fe2.water(); // FireEngine타입으로 쓸수 있음
Car c = new Car(); // Car타입 객체 생성
FireEngine fe3 = (FireEngine)c; // 조상 -> 자손으로 형변환인데 컴파일 통과.
// Car 타입 c는 멤버가 4개, water()가 없음.
// fe3.water(); // => 에러
}컴파일 에러! Car 타입의 참조변수로는 water()를 호출할 수 없다.
※ 참조변수가 가리키는 객체(new)의 타입이 무엇인지 꼭 확인하자.
instanceof 연산자
1) 확인, 형변환 해도 되는지
2) 형변환
- 참조변수의 형변환 가능여부 확인에 사용. 가능하면 true 반환(조상-자손)
- instanceof의 연산결과가 true이면, 해당 타입으로 형변환이 가능.
System.out.println(fe instanceof Object); // 결과 : true
System.out.println(fe instanceof Car); // 결과 : true
System.out.println(fe instanceof FireEngine); // 결과 : true
Object obj = (Object)fe; // 형변환 가능
Car c = (Car)fe; // 형변환 가능자기 자신도 다 참(true), 조상에 대해서 다 참(true)이다.
참조변수의 형변환 왜함? (타입 일치시키려고)
= 참조변수(리모컨)을 변경함으로써 사용할 수 있는 맴버의 갯수를 조절하기 위해서
instanceof 언제 사용하는지?
참조변수를 형변환 하기전에 여부를 확인하기 위해
매개변수의 다형성
장점
1) 다형적 매개변수
2) 하나의 배열로 여러종류 객체 다루기
참조형 매개변수는 메서드 호출시, 자신과 같은 타입 또는 자손타입의 인스턴스를 넘겨줄 수 있다.
class Product {
int price;
int bonusPoint;
Product(int price){ // 생성자
this.price = price;
bonusPoint = (int)(price/10.0); // 제품 가격의 10%
}
}
class Tv1 extends Product {
Tv1 () {super(100);} // 가격 : 100만원
@Override
public String toString() {return "TV";}
}
class Computer extends Product {
Computer() { super(200);} // 가격 200 만원
@Override
public String toString() {return "computer";}
}
class Buyer {
int money=1000;
int bonusPoint = 0;
void buy(Product p) { //Product의 자손 Tv1, Computer 매개변수로 전달
if (money < p.price) {
System.out.println("잔액이 부족하여 물건으 살수 없습니다.");
return;
}
money -= p.price;
bonusPoint += p.bonusPoint;
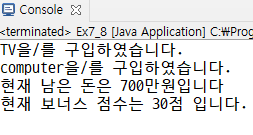
System.out.println(p + "을/를 구입하였습니다.");
}
}
public static void main(String[] args) {
Buyer b = new Buyer();
// buy(Product p) 제품구매(객체 생성)-> buy의 매개변수로 전달
b.buy(new Tv1()); // tv구매 :
b.buy(new Computer()); //Computer 구매
System.out.println("현재 남은 돈은 " + b.money + "만원입니다");
System.out.println("현재 보너스 점수는 " + b.bonusPoint +"점 입니다.");
}Product p = new Tv1();
b.buy(p);
= b.buy(new Tv1());
여러 종류의 객체를 하나의 배열로 다루기 (다형성의 장점)
: 조상타입의 배열에 자손들의 객체를 담을 수 있다.
= 하나의 배열에 여러 종류의 객체 저장

class Buyer2 {
int money=1000;
int bonusPoint = 0;
Product[] cart = new Product[10];
int i=0;
void buy(Product p) {
if (money < p.price) {
System.out.println("잔액이 부족하여 물건으 살수 없습니다.");
return;
}
money -= p.price;
bonusPoint += p.bonusPoint;
System.out.println(p + "을/를 구입하였습니다.");
cart[i++] = p; // 카트배열에 객체 저장
}
}
▶ Vector 클래스 : 가변배열 가능
public class Vecter extends AbstractList...
protected Object elementData[];Object 배열 = 모든 종류의 객체 저장 가능
예제) Ex7_9
class Buyer3 {
int money=1000;
int bonusPoint = 0;
Product2[] cart = new Product2[10];
int i=0;
void buy(Product2 p) {
if (money < p.price) {
System.out.println("잔액이 부족하여 물건으 살수 없습니다.");
return;
}
money -= p.price;
bonusPoint += p.bonusPoint;
cart[i++] = p;
System.out.println(p + "을/를 구입하였습니다.");
}
void summary() {
int sum = 0;
String itemList = "";
for (int i = 0; i < cart.length; i++) {
if(cart[i] == null) break;
sum += cart[i].price;
itemList += cart[i] + ", ";
}
System.out.println("구입하신 물품의 총금액은" + sum + "만원입니다.");
System.out.println("구입하신 제품은" + itemList + "입니다.");
}Test

public static void main(String[] args) {
Buyer3 b = new Buyer3();
b.buy(new Tv2());
b.buy(new Audio());
b.buy(new Computer2());
b.summary(); // cart배열 출력
}