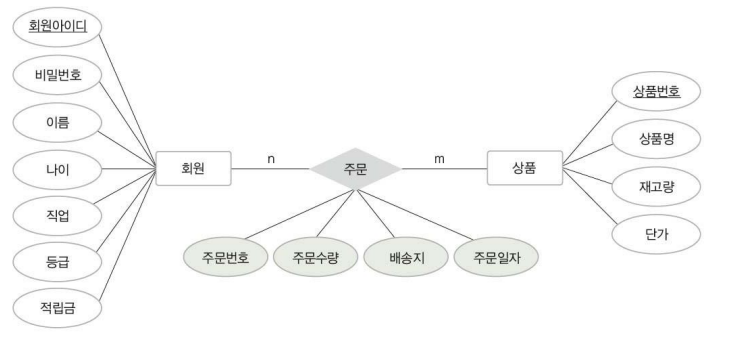
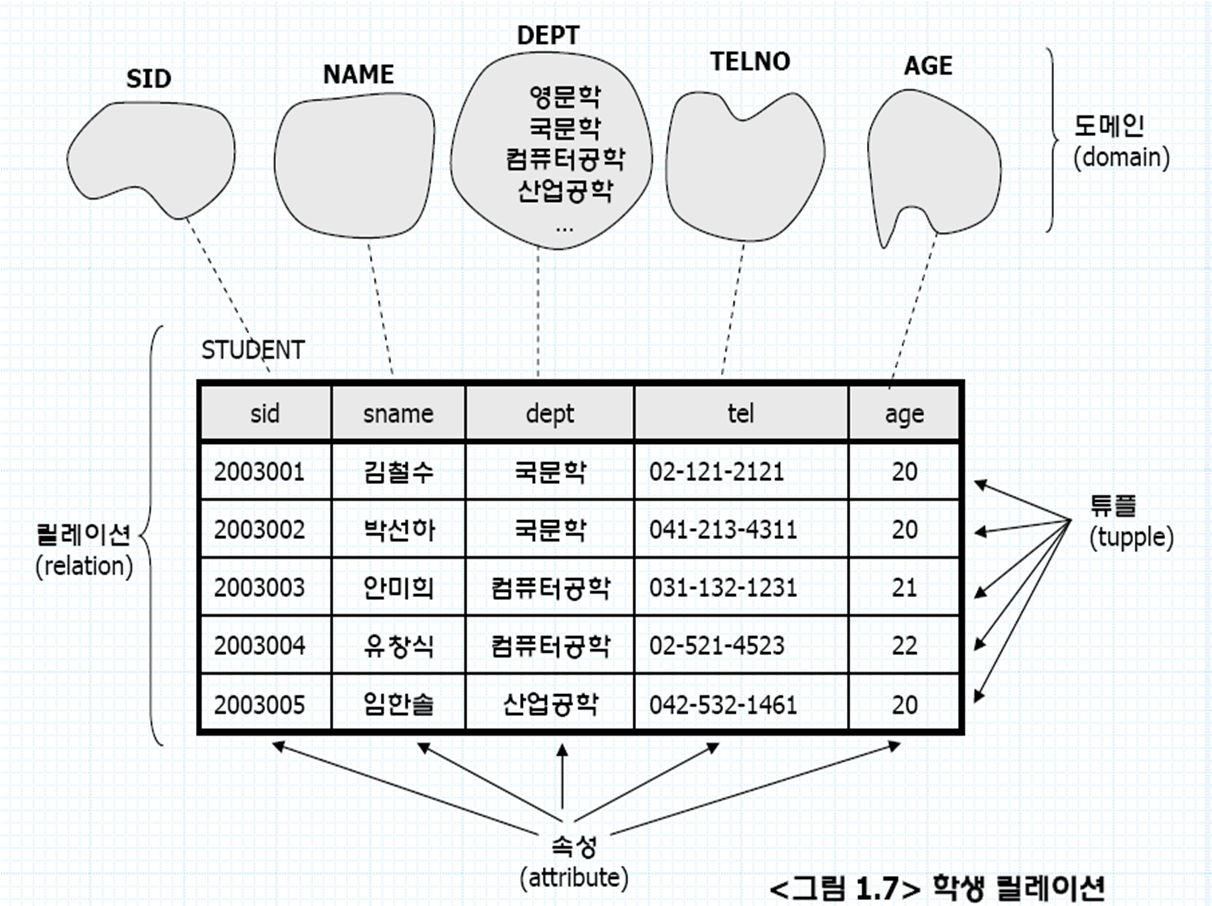
< 정규화 과정과 함수 종속성 >
■ 정규화 란?
- 관계형 데이터베이스 설계시 중복을 최소화 하도록 데이터를 구조화 하는 작업 (표를 세분화 시킨다.)
- 정규화를 하는 목적 - 이상현상(Anomaly)이 있는 관계를 재구성함으로 써 바람직한 스키마로 구성
■ 정규화의 종류
1. 제 1 정규화(1NF) : 다가속성 제거 (속성값은 2개 이상이면 안된다)
2. 제 2 정규화(2NF) : 부분 함수 종속 제거
3. 제 3 정규화(3NF) : 이행 함수종속 제거
ㄴ 3.5 정규화 (B.C)
4. 제 4 정규화(4NF) : 다치종속 제거
5. 제 5 정규화(5NF) : 조인종속 확인
비정규형 테이블 => 제1정규화 (도메인 원자값 조건 만족)
▶ 제 1 정규화
: 모든 속성은 반드시 하나의 값을 가져야 함. (다가속성 Multivalued Attributes, 복합속성 Composite Attributes)
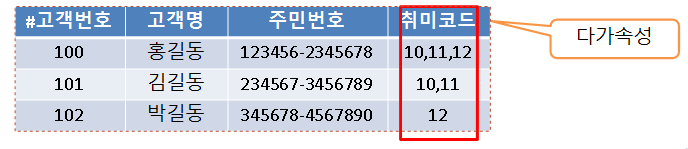
1) 1정규화 대상
- 다가 속성이 사용된 릴레이션
- 복합 속성이 사용된 릴레이션
- 유사속성이 반복되는 릴레이션
- 중첩 릴리에션
- 동일 속성이 여러 릴레이션에 사용된 경우
2) 도메인 원자값의 조건
- 반복그룹이 존대해선 안된다.
- 모든 행은 식별자로 완전하게 구분되어야 한다.
※ 다가 속성인 부분은 테이블을 분리한다.

▶ 제 2 정규화 (복합Key일때)
- 주 식별자가 두개이상의 릴레이션(복합키)일때 발생한다.
- 모든 비 식별자는 주 식별자에 완전 함수종속이 되어야 한다.
- 비식별자 중 주 식별자 전체에 종속적이지 않은 속성을 찾아 제거하고 새로운 릴레이션을 생성한다.
▶ 함수종속 : Functional dependent A속성이 B속을 유일하게 식별할수 있다.
- A속성 값이 변동되면 B속성값이 변동되어야 한다.
=> 결정자(기준이되는 값,x)와 종속자(결정자에 의해 정해질수 있는 값,y) Y=F(x)
※ 주민등록번호는 결정자이지만 주민번호는 기본키는 안된다. (주민번호는 반드시 암호화해야함)
법적으로 사용이 제한되는경우 기본키로 쓸 수 없음

- 두개의 식별자(#A, B)중 C는 #A와 관련없고 #B에 종속되어 있다. => 부분 함수종속 발생!
- 원본 테이블에서 C를 제거하고 #BC를 별도로 새로운 릴레이션으로 작성한다.


▶ 제 3 정규화 (이행 종속 제거)
▷이행종속 : x->y->z 종속이 됨. z는 x에 간접적으로 종속되어있음. 직접종속인 x,y,z를 별도 분리
- 비 식별자 간에 발생하는 이행적 종속성과 관련된 정규화
- A-> B -> C


※ 기본주소 -> 우편번호에 종속됨.
결정자는 우편번호. 이행종속 된것을 별도의 테이블로 구성을 해야함.
▶ 3.5 B.C 정규화 (Boyece and Codd)
: 제3 정규화를 보강한 정규화
제3 정규화를 만족하면서 모든 결정자가 주 식별자여야 한다.
모든 식별자는 후보식별자 이여야 한다.
모든 3정규화는 보이스코드는 아니다.
모든 결정자가 후보자 집합에 속해야 한다.
▶ 제4정규화(다가종속 = 다치종속 제거, MVD)
- 조건 : 1~3정규형 + B.C 정규형을 만족하고 다가종속이 발생되어진 경우
- 한 릴레이션에 다가속성이 두 개 이상 존재할때 발생

과목 =>> { 교재}
과목 =>> { 교수}
과목 =>> { 교재, 교수} 로 분리

▶ 제5정규화(조인종속 확인)
: 테이블을 분할 했을때 분할된 테이블을 조인했을때 데이터의 손실없이 조인되는것
A,B,C,D => AD, BC 분리 / 조인 / ABCD가 나와야 하는데 ABC 가 됨 => 손실 발생(제5정규화 위배)
무손실 조인을 만족해야 함.

※ 무손실 조인 : 릴레이션을 분해한 후 공통식별자 속성으로 조인하였을 때 데이터의 손실없이 원본의 릴레이션 값과
동일한 값이여야 함
※ 비부가적 조인 : 조인한 결과 원본 릴레이션에서는 없는 데이터가 있는경우
| 구 분 | 제거 대상 | 특징 |
| 1차 정규화 | 다가속성, 복합속성, 반복속성, 중첩릴레이션 제거 | 모든 속성의 도메인이 원자값으로만 구성 |
| 2차 정규화 | 부분 함수종속 제거 | 복합키 일때 발생 모든 속성이 기본키에 완전 함수종속이 되어야함 |
| 3차 정규화 | 이행종속 제거 | 모든 속성을 직접종속으로 분리 |
| 3.5 B.C 정규화 | 종속자가 키(Key)에 포함된 함수종속 제거 | |
| 4차 정규화 | 다가종속(다치종속) 제거 | |
| 5차 정규화 | 조인종속 확인 | 릴레이션 분해 후 조인하였을때 무손실 조인이어야함. |
▷역정규화/반정규화
: 정규화를 시키지 않아서 얻는 이점이 정규화를 시켜서 얻는 이점보다 크기 때문에 정규화를 하지 않음
작은 오류만 발생되어질 경우에만 가능(갱신, 삭제, 삽입 이상이 없을 때 가능)
반 정규화도 정규화의 일부중 하나이다.
※ 정규화 이점
- 업무요건의 변경에 유연하다. 확장성 좋음
- 인덱스 수가 감소하고 특정 요건 초회할 때 SQL 요건이 단순해짐
※ 비정규화
- 업무요건이 변경되면 해당되어지는 자료가 원치않은 결과를 되돌려져일수 있음. 확장성이 부족함(DB취약)
- 인덱스의 수가 증가하고 특정 요건 조회할 때 SQL요건이 많고 복잡해짐. 불필요한 중복 발생
- 개체(엔터티)의 속성이 추가될 가능성이 없을때 사용 가능
▷ 종속성과 폐포(closure)
= x가 결정자이고 y,z가 종속자이면 이때 x의 폐포는? x,y,z의 집합이 x+이다, (자기 자신을 포함해서)
▷ 종속성 추론 규칙
아노말리(Anomaly) = 데이터의 이상현상
이상현상의 종류 3가지
- 갱신이상 Update Anomaly
- 삽입이상 Insert Anomaly
- 삭제이상 Delete Anomaly
허용되어질수 있는 아노말리 : 업데이트, 인써트(삽입)
허용되어질수 있는 아노말리 : 딜리트(삭제)
=> 아노말리를 해결하기위해 정규화 해야한다
번외1)
규칙2 : 다:다 관계는 릴레이션으로 변환한다(논리적 모델에서는 다:다 허용X)
변환되는 과정에서 테이블 분리가 발생되어질수 있다. 두개의 부모로부터 받은 릴레이션으로 그 기본키를
새 릴레이션의 자식의 기본키로 만든다.(식별관계)
규칙3 1:다 관계는 왜래키로 표현한다 X => 관계의 속성이 포함되는 경우는 관계가 특별한 값을 가져야함
=>릴레이션으로 만드는 방법이 효율적일수 있다.
1:다 관계에서 속성이 없을때는 왜래키로 표현한다 O/꼭 기본키로 되는건아님.
1:다 관계에서 속성이 있을때는 릴레이션으로 만드는게 더 좋을수도 있음
규칙4 1:1관계는 서로 왜래키로 주고 받는다, 필수참여이면 하나의 릴레이션으로 통합시킨다.
불필요한 항목이 중복되어질수 있다.
모든 개체가 필수적으로 참여하면 릴레이션을 하나로 합친다
규칙5 다중값 속성은 릴레이션으로 변환한다. (제1정규화로 만족하는 형태로 만들어야함)
부하직원 : 다중값(여러가지의 속성이 나올수 있음) => 별도로 릴레이션 작성
원본의 기본키+부하직원 복합키 => 자식테이블(식별자) : 부모테이블의 기본키가 자식테이블의 기본키가 되어서
=> 제1정규화
모든 컬럼은 값이 하나이여야 한다
모든 일반 컬럼은 기본 키 속성에 종속되어야 함.(NILL값 X, 중복X)
이것을 위배한다 => 제1 정규화 시켜야함
BUYER : 거래처
날짜가 없음, 별도로 관리할수있는
매입에 관련된거 BUYPRO = 매입 테이블 => 단가는 있으면 안됨. BUY_COST 중복이 발생될수 있다
=>이상현상이 발생될수 있음 (업데이트 Anomaly(이상))
=================================================================
=========================================================
<오라클 데이터베이스 교안PPT>93p
테이블 명세서 작성
N.N - not null =>null값을 허용하지 않음
멤버변수 : 메소드 위치에서 선언되어지는 변수, 자동초기화
지역변수 : 메소드, 블록 안에서 선언되어지는 변수
스태틱변수
논문 [소프트웨어 위기론] 참고
오라클은 숫자위주 프로그램
초기값 무조건 null값으로 들어감
null : 길이를 갖지 않는 데이터(length:x)
null값이 들어간 식 값 = none
spacebar 40(16진수)
자바는 문자열은 "" 쌍따옴표 """" = white space
오라클은 문자열을 ''단따옴표 /'대한민국'/
=>''''단따옴표*2번= white space = null값으로 인식한다. 릴터럴 상수
한글을 영어로 바꾸는 사전이 필요함 : 자료사전(외국프로그램이라서 한글인식이 잘 안됨)
EXERD
명령어로 테이블로 만들어보자
-------------------------------------------
Developer -sql워크시트(초록색)-본인계정
2022-1108-1)SQL(Structure Query language)
- 구조적 질의 처리기
. 변수, 분기문, 반복문 등이 존재하지 않음
- 1973년 SQUARE로부터 출발
- 1986년 ANSI-86표준안(1988년 ISO인정) : SQL 법적 기준
- 1992, 1999년 표준안 개정
- 명령의 분류
. 검색명령 : SELECT
. 조작어 DML(Data Manipulation Language) : INSERT/UPDATE/DELETE
. 정의어 DLL(Data Definition Language) : CREATE/ALTER/DROP 등
. 제어어 DLC(Data Control Language) : GRANT/REVOKE/COMMIT/ROLLBACK/SAVEPOINT 등
객체 생성은 반드시 CREATE 사용
사용자 권한부여 GRANT
REVOKE 권한회수 =>관리자 사용
COMMIT : 트랜잭션이 끝나면 정상적으로 저장되도록 만드는 것
ROLLBACK : 트랜잭션 전으로 돌아가기
1. CREATE TABLE 명령 (가장 표준적인 방법)
- 테이블 생성 명령
(사용형식)
CREATE TABLE 테이블명 (
컬럼명 데디터타입[(크기)] [NOT NULL][DEFAULT 값] [,]
.
.
컬럼명 데이터타입[(크기)] [NOT NULL][DEFAULT 값] [,]
[CONSTRAINT 기본키설정명 PRIMARY KEY(컬럼명[,컬럼명,....])[,]]
[CONSTRAINT 왜래키설정명 FOREIGN KEY(컬럼명)
REFERENCES 테이블명(컬럼명)] [,]
.
.
[CONSTRAINT 왜래키설정명 FOREIGN KEY(컬럼명)
REFERENCES 테이블명(컬럼명)];
. '데이터타입' : 오라클에서 사용할 수 있는 자료타입 기술
- 문자열타입 : CHAR, VARCHAR, VARCHAR2, CLOB, LONG 등
- 숫자타입 : NUMBER
- 날짜타입 : DATE, TIMESTAMP
- 이진자료 : RAW, BLOB, BFILE 등
. 'DEFAULT 값' : 사용자가 기술하지 않았을 경우 기본적으로 입력되는 값
. '기본키설정명' : 기본키 설정에 붙여지는 이름으로 고유한 이름이여야 함
. 'PRIMARY KEY(컬럼명,..)' : 기본키로 사용되는 컬럼명
. '왜래키설정명' : 왜래키 설정에 붙여지는 이름으로 고유한 이름이여야 함
. 'REFERENCES 테이블명(컬럼명)' : 부모테이블명과 부모테이블에서 사용된 컬럼명
--------------------------
사용자 정의 단어 기술 유의점
$ 되도록이면 쓰지마라. 풀네임으로 써라, 한글은 쓰지마라
데이터 타입은 크게 4가지.
자바=문자의 배열이 문자열
오라클은 문자가 없다 =>문자열, 문자의 집합체로 인식''
문자열을 나타내는 데이터 타입 여러개
CHAR : 고정길이 문자열, 데이터 저장될 길이가 정해져 있음. 왼쪽부터 저장됨.오른쪽은 공백
데이터가 길면 저장 불가능.=>오류(데이터가 중간에 짤리지 않음)
나머지 가변길이 VARCHAR, VARCHAR2, CLOB, LONG : 데이터 길이만큼만 쓰고 운영체제에 반납함.
가변길이의 표준 : VARCHAR 최대 4000바이트 저장 (오라클은 VARCHAR 안쓴다 => VARCHAR2를 써라)
LONG : 문자열 저장 최대 2G Byte 저장 가능 (현재는 잘 안씀=>더이상의 서비스개선 중지됨)
ㄴ 하나의 테이블의 한 컬럼만 쓸수 있기 때문에 =>CLOB를써라
CLOB : 4G Byte 저장 가능
VARCHAR2 많이사용 - CHAR 두번째 많이 사용 - CLOB 가끔 사용
숫자타입 : NUMBER(정수, 실수 둘다 사용 가능)
날짜타입 : TIMESTAMP : 십억분의 1초까지 사용 가능
defualt 값 : 사용자가 생략하면 기본적으로 들어갈 값을 설정해줌
null값 => 연산하면 연산 불가
null 대신에 0 들어가게 하라 : defualt = 0;
[,] 콤마가 붙는다 : 오라클은 statement 명령문 - 명령문 안에 절[(왜래키 설정)]
=> [컬럼 절이 아직 안 끝났다.] CREATE 명령문이 아직 안끝났다.
CONSTRAINT 기본키 설정 : 컬럼명 중 하나 => PRIMARY KEY
메타데이타를 가지고 있는 것은 시스템 테이블
2개의 부모에서 가져온 2개의 왜래키
FOREIGN KEY(컬럼명-CREATE 컬럼명 중 1) => 2개의 절로 써야함
REFERENCES (참조하는)테이블명1(컬럼명)] => 테이블 명을 2개 동시에 쓸수 없으므로
REFERENCES (참조하는)테이블명2(컬럼명)] => 2줄을 써야함(컬럼명은 달라야함)
(컬럼명, 콤마로 쓸수있음)
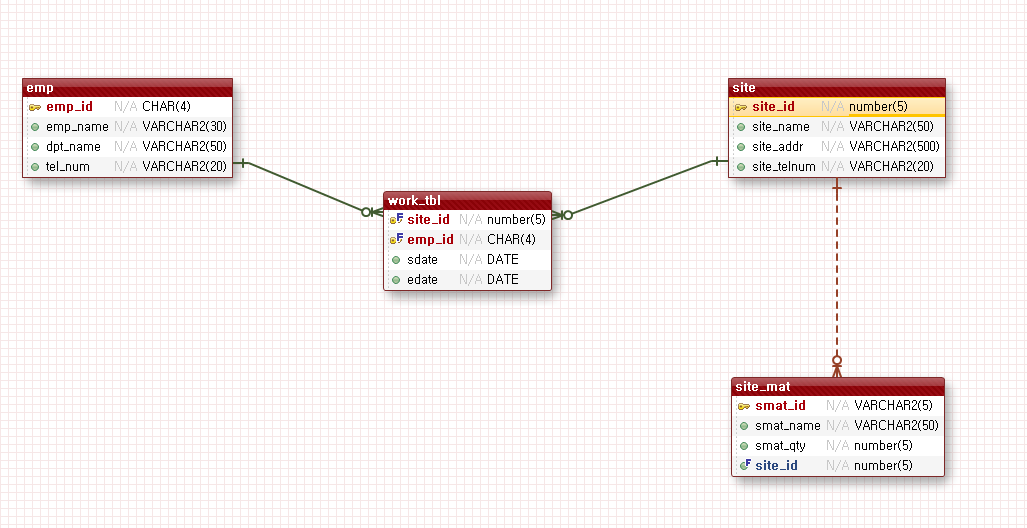
예제) 가장 상위의 테이블 먼저 작성해야함.
1) EMP, SITE
2) WORK, SITE_MAT
EMP_NAME VARCHAR2(30) NOT NULL, (N.N=X) NULL값을 허용하지 않음
TEL_NUM VARCHAR2(20), 왜래키 없음 기본키만 있음
CONSTRAINT pk_EMP_ID 소문자로 써도됨. 나중에 저장은 대문자로 출력
emp 테이블 - 제약조건 탭
constraint name
1. emp_id
2. sys_c007050
'DataBase' 카테고리의 다른 글
| 22111~14 데이터 베이스 오라클 SQL : 연산자 (0) | 2022.11.16 |
|---|---|
| 221115 데이터 베이스 오라클 SQL : 기타 연산자 (0) | 2022.11.16 |
| 데이터베이스 03일 정리 (0) | 2022.11.11 |
| 데이터베이스 02일 정리 (0) | 2022.11.11 |
| 데이터베이스 01일 정리 (0) | 2022.11.11 |